From Pilot to Production: Why 82% of AI Projects Fail
Ronnie Miller
July 3, 2025
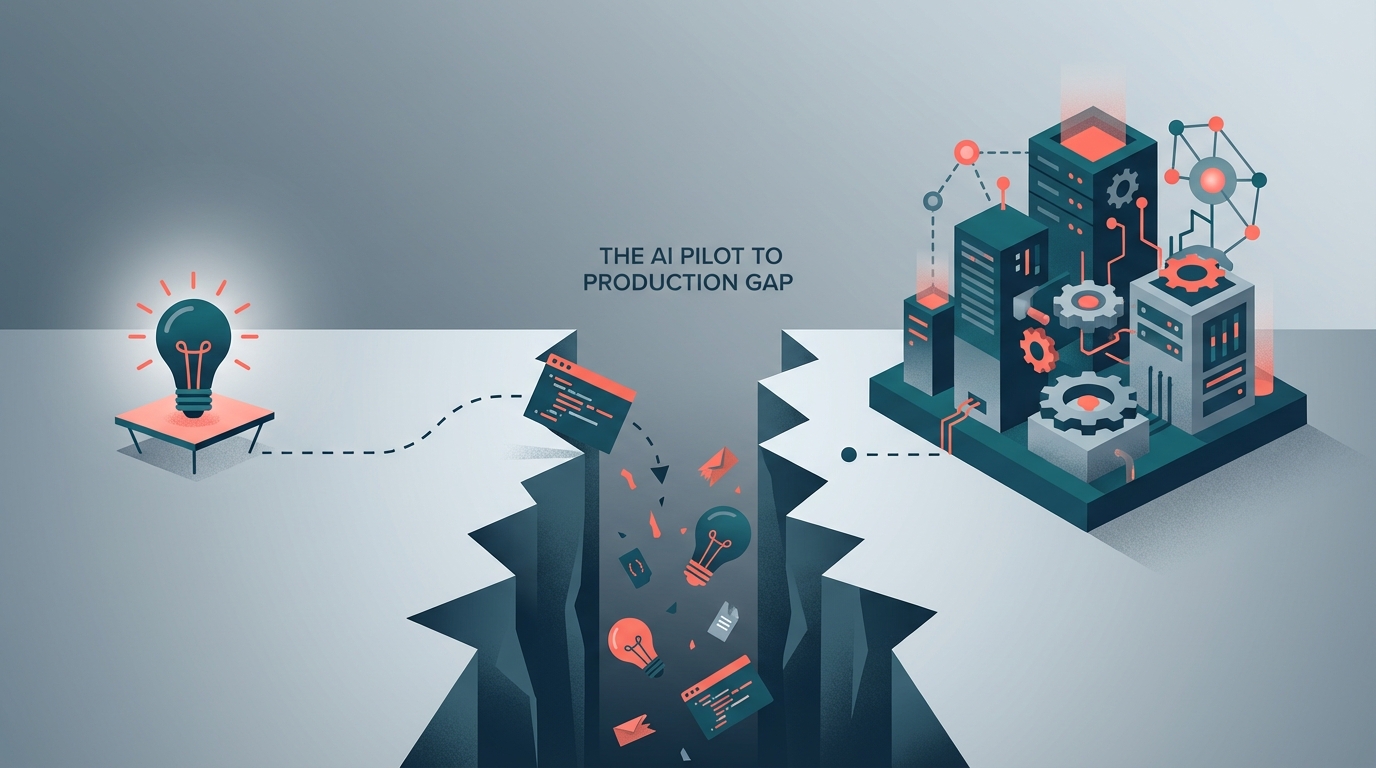
The numbers are ugly. RAND Corporation says 80% or more of AI projects fail. Gartner puts it at 85%. MIT's latest research on generative AI is even worse: 95% of gen AI pilots deliver zero measurable return on investment. Whatever the exact number, the pattern is the same: impressive demo, enthusiastic stakeholders, a few months of momentum, and then... nothing ships.
Having spent 15+ years building software and the last few years focused specifically on AI engineering, I've watched this play out over and over. The team gets excited. Leadership gets excited. The demo looks incredible. And then reality hits.
The demo-to-production gap isn't a technology problem. It's an engineering discipline problem. And until we start treating it that way, the numbers aren't going to change.
The Demo Lie
Here's the thing nobody talks about: a demo is built to impress, not to survive.
A demo runs on a laptop with clean data. It doesn't handle latency. It doesn't handle errors. It doesn't deal with authentication, logging, monitoring, or the thousand edge cases that show up when real users interact with a system in ways you never anticipated.
A demo ignores cost. It ignores data drift. It ignores the fact that the model's training data looks nothing like what it'll see in production. And everyone in the room nods along because the output looks right on the screen in front of them.
I've seen teams spend three months building a proof-of-concept, show it to leadership, get a green light, and then spend the next twelve months discovering that the "concept" they proved was only the easy part. The "concept" in proof-of-concept is supposed to mean the whole idea: the process, the workflow, the people, the integration points. If your PoC doesn't validate those things, it's not a proof-of-concept. It's a tech demo with a fancy name.
The data backs this up. Research from Dimensional Research found that only 4 out of 33 AI proof-of-concepts actually graduate to production. That's an 88% failure rate just at the PoC stage. Before you've even tried to build the real thing, the odds are already stacked against you.
And these aren't small companies with no resources. McDonald's partnered with IBM for three years to build drive-thru AI ordering. Three years, two massive companies, and they pulled the plug. Zillow built an AI-powered home buying algorithm that was supposed to revolutionize their business. It cost them $500 million in losses and 25% of their workforce. The demos, I'm sure, looked fantastic.
The Real Reasons Projects Die
Most articles about AI project failure give you surface-level answers. "The technology wasn't ready." "The team lacked skills." "The budget was too small." Those aren't wrong, but they're not the real story either. Here's what I actually see killing projects.
Nobody defined the actual problem
This is the one that gets me every time. A team decides they need AI. They pick a use case. They start building. And nobody stops to ask: what specific business problem are we solving, and how will we know if we've solved it?
RAND's research is blunt about this. They found that "misunderstandings about what the AI is intended to do" are the single most common reason AI projects fail. Not technical limitations. Not data problems. Misunderstandings about intent.
Teams optimize for the wrong metrics. They build solutions looking for problems. They chase accuracy scores on benchmarks that don't map to business outcomes. I've seen a team spend six months building a model with 95% accuracy on their test set, only to discover that the 5% it got wrong were the exact cases the business cared about most.
The data is a mess
Everyone wants to talk about models. Nobody wants to talk about data. And the data is where projects actually live or die.
Gartner's research says 85% of AI projects fail due to poor data quality. Not poor models. Poor data. The training data doesn't represent production conditions. The data pipeline is fragile. There's no validation. Labels are inconsistent. Critical fields are missing or filled with garbage.
Nobody wants to spend six months building data infrastructure. It's not exciting. It doesn't demo well. You can't show a data pipeline to the board and get a standing ovation. But that's the actual work. That's where the 18% that succeed are investing their time.
The handoff kills it
Here's a pattern I've seen destroy more projects than any technical limitation: the data science team builds a model in a Jupyter notebook. They hand it off to the engineering team to "productionize." The engineering team opens the notebook and discovers that the model expects data formats that don't exist in production, depends on libraries that conflict with the existing stack, and requires infrastructure that nobody budgeted for.
What looked 90% complete is actually 10% done. The model works. Everything around it doesn't exist yet.
This handoff problem is structural. Data scientists and engineers speak different languages, use different tools, and optimize for different things. When you separate them and create a handoff point, you're building in a failure mode. It's like having architects design a building and then handing blueprints to construction workers who've never met them. The result is predictable.
No production infrastructure
I can't tell you how many AI systems I've seen running in production with zero monitoring. No alerts when the model's performance degrades. No CI/CD pipeline. No rollback strategy. No logging that would tell you what went wrong after the fact.
Research shows that 91% of machine learning models degrade in performance over time. The data changes. User behavior shifts. The world moves on, and your model is still making predictions based on last year's patterns. If nobody's watching, nobody notices until a customer calls to complain. Or worse, they don't complain. They just leave.
This isn't a new problem. Traditional software has solved it with decades of operations practices. But for some reason, a lot of AI teams act like monitoring is optional. Like their model is special and won't degrade. It will.
The org isn't ready
This is the least technical reason and arguably the most important one. Studies consistently show that roughly 70% of AI implementation challenges are people and process problems, not technology problems.
I've watched a model with 90%+ accuracy gather dust because the supervisors who were supposed to use it didn't trust auto-generated outputs. Nobody involved them in the design process. Nobody trained them. Nobody addressed their legitimate concerns about what happens when the model gets it wrong and they're the ones who have to answer for it.
You can build the most accurate model in the world. If the people who need to use it don't trust it, understand it, or want it, you've built nothing.
What the Winners Do Differently
So what about the roughly 18% that make it? They're not smarter. They don't have better technology. They have better discipline. Here's what I see consistently in projects that actually ship and deliver value.
They start with business pain, not technology
The successful projects I've been part of or studied all start the same way: with a specific, painful business problem that someone is desperate to solve.
Look at Air India. They didn't say "let's do AI." They said "we handle millions of customer queries and our response times are terrible." Specific constraint. They built a specific solution around that constraint. The result: over 4 million queries handled, 97% automation rate. That works because the problem was clear, the success metric was obvious, and the technology was shaped to fit the problem rather than the other way around.
Before you write a line of code, you should be able to finish this sentence: "This project succeeds if _____." If you can't, stop.
They invest in data, not models
The teams that succeed spend 50-70% of their budget on data readiness. Not on the model. Not on the infrastructure. On making sure the data is clean, accessible, representative, and properly governed.
That sounds boring. It is boring. It's also the single biggest predictor of whether an AI project succeeds or fails. The model is the easy part. Getting it the right data, in the right format, reliably and consistently, is the hard part.
Engineers and data scientists work together from day one
No handoff. No "build the model then throw it over the wall." The engineer who's going to deploy and maintain the system is in the room from the first conversation. They're making decisions together about architecture, data formats, infrastructure requirements, and deployment strategy.
When the data scientist understands production constraints and the engineer understands model requirements, you skip the six months of "productionization" that kills most projects.
They build monitoring and rollback from the start
Not after launch. Not "when we have time." From the start. Before the model is even trained, the team has answered: How will we know if this model is performing well? How will we know if it's degrading? What happens if we need to roll back to the previous version at 2 AM on a Saturday?
These aren't nice-to-haves. They're requirements. If you wouldn't ship a web application without monitoring and the ability to roll back a bad deploy, why would you ship an AI system that way?
They design for drift
Models degrade. This is a fact. The successful teams plan for it from the beginning. They build retraining pipelines. They set up data monitoring to detect when input distributions shift. They define thresholds for when a model needs to be retrained or replaced.
This is the difference between a system that works on launch day and a system that works six months later. If your plan doesn't include model maintenance, your plan has an expiration date.
They buy where they can, build only where they must
Here's a stat that should change how you think about AI projects: buying or licensing existing AI solutions succeeds roughly 67% of the time. Building custom solutions internally? About 22%.
The winners are ruthlessly pragmatic. They don't build custom models for problems that existing APIs or platforms solve well. They save their custom development budget for the things that are genuinely unique to their business. Everything else, they buy, integrate, and move on.
The Engineering Discipline Nobody Wants to Talk About
Here's my unpopular take: AI isn't special. It's software.
It needs the same engineering discipline as any production system. Testing. Monitoring. Error handling. CI/CD. Rollback capability. Logging. Alerting. Documentation. Code review. Version control. Dependency management.
None of that is glamorous. None of it makes for a good conference talk. But it's the difference between a system that runs reliably in production and a system that works on your laptop.
The AI industry has been dominated by researchers and data scientists. These are brilliant people doing incredible work. But the skillset that builds a great model is not the same skillset that ships and maintains a reliable production system. What the industry needs, desperately, is more software engineers who understand how to take something that works in a notebook and turn it into something that works at 3 AM when the on-call engineer gets paged.
MLOps, LLMOps, whatever you want to call it, isn't optional. It's not a nice-to-have for mature teams. It's the difference between a science project and a business asset. The model is maybe 20% of a production AI system. The other 80% is everything around it: the data pipeline, the serving infrastructure, the monitoring, the feedback loops, the error handling, the graceful degradation when something goes wrong.
I've been building production software for a long time. The patterns that make software reliable haven't changed just because we're running a neural network instead of a rules engine. If anything, the non-deterministic nature of AI systems means we need more engineering discipline, not less. You need to test more carefully, monitor more closely, and plan for failure modes that are harder to predict.
We don't build proof-of-concepts and call it done. We ship production-grade AI systems with monitoring, error handling, and real-world resilience. That's not a tagline. That's an engineering philosophy.
A Practical Checklist
Before your next AI initiative, answer these honestly. Yes or no. No "kind of." No "we'll figure it out later."
- Can you state the business problem in one sentence? Not the technology. Not the approach. The problem you're solving for the business.
- Do you have a specific, measurable success metric? Not "improve efficiency." A number. A threshold. Something you can point to and say "we did it" or "we didn't."
- Is the data clean, accessible, and representative? Not "we have data somewhere." Is it actually ready? Have you looked at it? Does it represent what you'll see in production?
- Do you have engineering capacity for production infrastructure? Not just data scientists. Engineers who will build the deployment pipeline, the monitoring, the error handling, the integration with existing systems.
- Is there an owner who will maintain this after launch? Not the team that built it. Someone whose job it is to keep it running, watch for degradation, and manage updates. A real owner, with real accountability.
- Have you budgeted for ongoing monitoring and maintenance? Not just the build cost. The ongoing cost. Models need retraining. Data pipelines need maintenance. Infrastructure needs updates. This isn't a one-time expense.
If you answered "no" to any of these, fix that before writing a single line of code. Every "no" on this list is a risk factor for ending up in the 82%.
The 82% failure rate isn't inevitable. It's the result of skipping the boring parts. The unglamorous work of defining clear problems, cleaning data, building infrastructure, setting up monitoring, and planning for maintenance.
The businesses that succeed with AI aren't the ones with the best models or the biggest budgets. They're the ones that treat AI like what it is: software that needs to be engineered, tested, monitored, and maintained. They invest in the unsexy stuff. They hire engineers alongside data scientists. They plan for day 200, not just day one.
That's not sexy. But it ships.
Need help making this real?
We build production AI systems and help dev teams go AI-native. Let's talk about where you are and what's next.