Why Most Multi-Agent Systems Won't Make It to 2027
Ronnie Miller
April 14, 2026
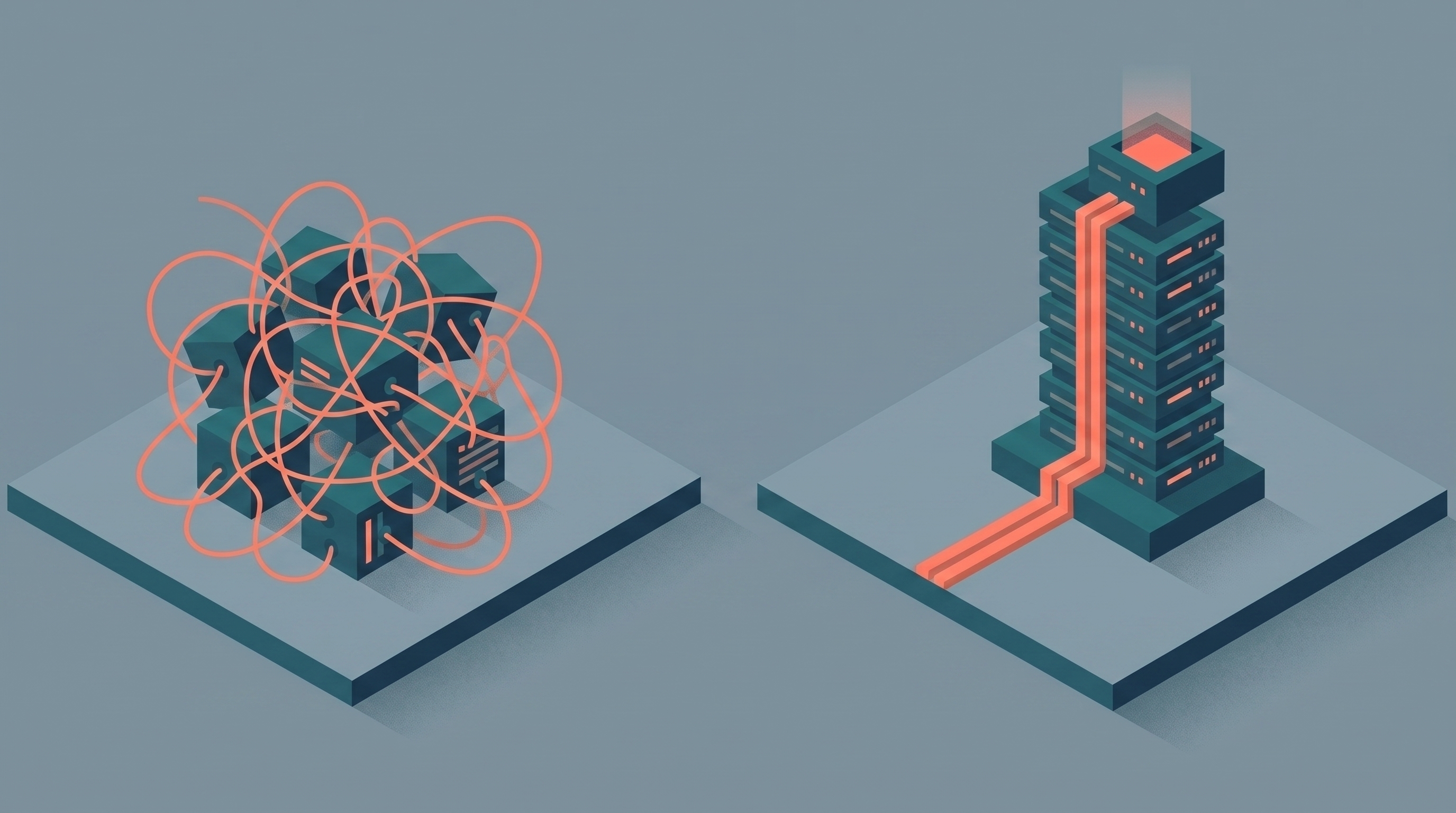
Multi-agent is the architectural pattern of 2026. Almost everyone is building one. Most won't make it.
OutSystems' April 2026 research puts AI agent adoption at 96% of enterprises. The same report says 94% are concerned about sprawl: duplicated agents, conflicting policies, unmonitored API spend, and technical debt accumulating faster than anyone can govern it. Gartner predicts 40% of agentic AI projects will be canceled by 2027. The gap between "we have agents" and "our agents are working" is enormous.
The first quarter of 2026 was the largest production stress test multi-agent systems have ever had. The results are in. I want to talk about what actually survived, why, and what most teams should be building instead of what they're building.
The Pattern That Doesn't Work
The default pitch for multi-agent systems is romantic. You have a team of specialized agents. They collaborate. They reason together. The whole is greater than the sum of the parts.
This is the version that mostly fails in production.
The technical name is "free-form peer collaboration": a set of agents that talk to each other without strict ordering, without an arbiter, without explicit handoff rules. The hope is that with the right prompts, they'll figure out how to coordinate. They almost never do.
What actually happens, based on the failure modes documented across Redis, GitHub Engineering, and a steady stream of practitioner reports through Q1: roughly 79% of multi-agent failures come from specification and coordination problems, not from infrastructure or model capability. The model is not the bottleneck. The way the agents are wired together is the bottleneck.
Three failure modes show up over and over:
Context inconsistency. Each agent has its own view of the world. When they pass messages, that view drifts. Agent A makes a decision based on data Agent B has already invalidated. By the time the system produces output, the agents are operating on incompatible assumptions and the result is incoherent. This is the largest single failure mode in multi-agent production systems.
Infinite handoff loops. Agent A doesn't know how to handle a request, so it hands off to B. B punts to C. C, lacking context that A had, sends it back to A. The cycle continues until something times out, or until your token budget catches fire. There is no arbiter and no termination condition. This is preventable, but only if you design for it on day one.
Token sprawl. Multi-agent systems consume roughly 15x the tokens of a single-agent chat for equivalent work. Every handoff carries context. Every coordination message costs money. The patterns that look elegant in a demo are economically catastrophic at production volume. Most teams discover this on their second monthly bill.
Together, these three account for the bulk of what's actually killing multi-agent projects this year. None of them are model problems. All of them are architectural choices that were never made explicitly.
What Q1 2026 Actually Validated
The patterns that survived production this quarter all share a common shape. They look less like a team and more like a workflow with a manager.
Orchestrator + workers, not peer-to-peer
The dominant production pattern in 2026 is what practitioners are now calling "orchestration": a single coordinator agent (or a deterministic controller) decides which specialized agent handles a given step. The specialists don't talk to each other directly. They talk to the orchestrator. The orchestrator owns routing, state, and termination.
This isn't as exciting as a swarm. It's much more reliable. You get a single place to enforce policies, a single point to attach observability, a single termination condition, and a single view of state. When something goes wrong, you know exactly where to look. When you need to add an agent, you don't have to renegotiate every other agent's contract.
If you're building peer-to-peer collaboration in 2026, you're building something that's already been retired in production environments that ran the experiment a year ago. There are bounded niches where it works. Most workflows are not those niches.
A persistent shared context store, not message-passing
Message-passing memory is the seductive pattern. Agent A sends Agent B a message. B responds. The conversation is the state. Looks clean.
It falls apart the moment two agents need to act on the same piece of information at different times. Agent C is starting work; Agent D has just updated the underlying record. If Agent C only knows what was passed to it five minutes ago, it operates on stale state. Multiply that across a long-running session and the system starts contradicting itself.
The systems that survive in production externalize state. There's a single shared context layer (a vector store, a structured database, often both) that every agent reads from and writes to. Messages between agents are pointers, not payloads. When an agent needs to know what's happened, it queries the store rather than relying on what was passed to it.
This sounds like more infrastructure. It is. It's also the difference between a system that holds together past minute 30 and one that doesn't.
Phase gates and explicit termination
Every surviving multi-agent system in production has explicit boundaries between phases. Plan, then research, then synthesize, then verify. Each phase has a defined output, a defined termination condition, and a gate that has to be cleared before the next phase begins.
Without phase gates, agents will happily continue working forever. They don't have an intrinsic sense of "done." They have to be told. The teams that get this right write it down: this phase ends when this artifact exists, and not before. This phase fails if N attempts pass without producing the artifact.
This is the part that most resembles regular software engineering. It is also the part that most multi-agent tutorials skip entirely.
Observability before launch, not after
I wrote about this in the observability post in January and I will keep saying it because it keeps being the difference: observability after the system is live is archaeology, not engineering. Multi-agent makes this more acute, not less. There are more moving parts. There are more places for things to drift. The cost of debugging without traces is higher because the search space is larger.
Distributed tracing, token accounting per agent, and automated evals running against every change set: these are not optional infrastructure. They are the floor.
The Sprawl Problem Nobody Wants to Talk About
Here's the thing the multi-agent conversation tends to dodge: most enterprises don't have one multi-agent system. They have a dozen, half of which were built without anyone in security or platform engineering knowing they exist.
OutSystems found that 38% of organizations are running a mix of custom-built and pre-built agents, and only 12% have a centralized platform to manage them. That leaves a vast middle: agents launched by individual teams, on individual budgets, with individual policies, no shared identity layer, no shared observability, and no shared context store. Each one looked reasonable in isolation. Together they look like a security and cost incident waiting to happen.
This is what 94% of leadership is actually worried about when they say "AI sprawl." It is not the abstract concept of having too many agents. It is the concrete reality that no one can answer basic questions like: which agents have access to customer data, who approved them, what's the total monthly spend across all of them, and which ones haven't been touched in 60 days.
The solution is unglamorous. A registry. Identity per agent. Centralized observability. Shared eval infrastructure. None of it is interesting. All of it is what separates teams who can keep adding agents from teams who hit a wall at five.
The Unfashionable Take
Most "multi-agent" systems should be single-agent systems with good tools.
The agent pattern that works in the largest number of production cases is one capable model with a curated set of tools and a clear scope. You give it the ability to retrieve information, to call APIs, to read and write to a context store, and you give it a tight specification of what it's supposed to do. That's it. No second agent. No orchestrator. No handoff.
Most of the cases where teams reach for multi-agent are cases where what they actually wanted was better tool design. They wanted a single agent that could handle a wider variety of inputs, and they reached for a multi-agent architecture because the literature suggested it. The literature is downstream of demos. Demos optimize for impressiveness, not reliability.
Reach for multi-agent when you have one of these specific situations: genuinely separable concerns that benefit from specialized prompts and contexts, hard governance boundaries that require separate identity per agent (regulated tasks, separation of duties), or workflows where the parallelism of multiple agents working independently is a performance requirement, not a stylistic choice. If your situation isn't one of those, simplify before you scale.
This is a less exciting recommendation than the one most consultants will give you. It is also the one that is shipping more reliably in production right now.
What to Do If You're Mid-Build
If you're already building multi-agent and you're starting to see the failure modes I described earlier, here's the order I'd address them in.
First, externalize state. Whatever your agents are passing to each other in messages, move it to a shared store. Have agents read from the store at the start of each step rather than relying on what was passed in. This alone fixes the largest category of failures.
Second, introduce an orchestrator if you don't have one. Even a deterministic controller (not an agent) is fine. The point is to have a single place that decides what runs next and what state it sees. Free-form collaboration is what you keep saying is fine when leadership asks; orchestration is what you actually need.
Third, set explicit termination conditions for every phase and every loop. "Stop after N retries" is a termination condition. "The agent decides when to stop" is not. The agents will not, on their own, decide to stop.
Fourth, instrument cost per agent. Not just total cost. Per agent, per request, per workflow. The 15x token multiplier means the only way to keep a multi-agent system viable is to know exactly which agent is responsible for which line item, and to optimize against that.
Fifth, get the registry and identity story sorted before you have ten agents. Sprawl is a governance problem that compounds. The fix is much cheaper at three agents than at thirty.
The Real Lesson From Q1
I've been doing this long enough to recognize the pattern. Every architectural trend goes through the same arc. There's the demo phase, where everything looks magical. There's the deployment phase, where teams discover the demo was hiding most of the work. There's the disillusionment phase, where the projects start failing publicly. And then there's the discipline phase, where the survivors codify what actually works and ignore everything else.
Multi-agent is somewhere between deployment and disillusionment right now. Gartner's 40% cancellation prediction is not a forecast about technology. It's a forecast about how many teams will skip the discipline phase and just stop trying.
The teams that will be running multi-agent systems profitably in 2027 are the ones building like it's already 2027. Orchestrator-led, externalized state, explicit phase gates, observability from day one, and a strong default toward "use one agent unless you can prove you need more." Boring engineering. The kind that doesn't make for a good conference talk and does make for a system that's still running in eighteen months.
If you're scoping or rescuing a multi-agent system and you want a second set of eyes on the architecture, that's exactly the kind of work my AI consulting practice is built around. The patterns above are the ones I keep applying.
They're not glamorous. They ship.
Need help making this real?
We build production AI systems and help dev teams go AI-native. Let's talk about where you are and what's next.