Your Dev Team Is Using AI Tools Wrong
Ronnie Miller
September 15, 2025
Every developer on your team has access to AI coding tools. Copilot, Cursor, Claude Code, ChatGPT. The list keeps growing. And if you ask around, most of them are using something. Some are even enthusiastic about it.
So why isn't your team measurably faster?
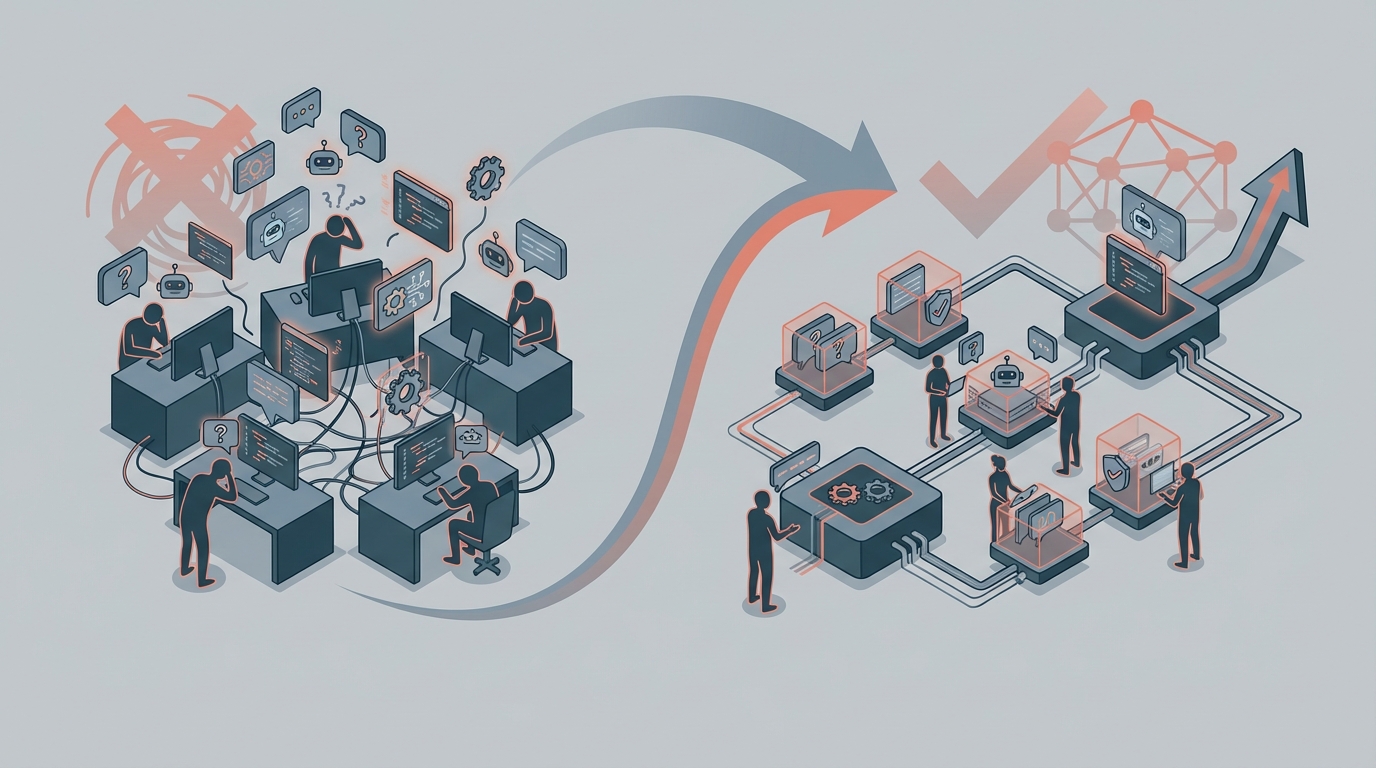
The answer isn't that the tools don't work. They do. The answer is that individual adoption without shared structure produces wildly inconsistent results. One developer swears by their setup. Another tried it for a week and gave up. A third is using it constantly but nobody's reviewed what it's actually producing. The net effect on your team's velocity? Unclear at best.
This is the "vibes-based AI" problem, and it's everywhere.
The Vibes-Based AI Problem
Here's what unstructured AI adoption looks like in practice. Each developer builds their own mental model of how to use AI tools. Developer A writes detailed prompts and gets solid results. Developer B pastes in error messages and takes whatever comes back. Developer C uses it for boilerplate but doesn't trust it for anything complex.
None of them are wrong, exactly. But none of them are building on each other's knowledge. Every developer is running their own independent experiment, and the results don't compound.
Compare this to how your team handles other aspects of development. You standardize on a linter. You agree on code review practices. You have CI pipelines that enforce test coverage. Nobody argues that these things slow them down. They create the shared foundation that lets the team move faster together.
AI tooling should be no different. But in most organizations, it's treated like a personal productivity hack rather than a team capability. And that's why the results feel uneven.
The biggest risk isn't that AI tools don't help. It's that without structure, the knowledge stays trapped in individual developers. When your best AI user leaves, their workflows leave with them. When a new developer joins, they start from scratch. There's no institutional learning happening.
Why Individual Adoption Doesn't Scale
Individual adoption creates three specific problems that get worse as your team grows.
Knowledge silos. Developer A figured out that providing project context and coding conventions in a system prompt dramatically improves output quality. That insight lives in their head and their personal configuration. Nobody else benefits. Multiply this across a dozen small discoveries and you have a team where AI effectiveness varies wildly from person to person.
No quality baseline. When AI-generated code goes through your existing review process, reviewers have no shared framework for evaluating it. Is this AI output good? Did the developer verify the test coverage? Did they check for hallucinated dependencies? Without shared expectations, review quality becomes inconsistent too.
No way to measure impact. Your team "uses AI tools," but is it actually making you faster? You can't answer that question without a baseline, and you can't establish a baseline when everyone is doing something different. So adoption continues on vibes: it feels faster, probably.
This is exactly the pattern we see with any engineering practice that starts as individual experimentation. At some point, the team has to graduate from "everyone does their own thing" to "we have a shared approach that we can improve together."
Three Layers of AI for Dev Teams
The teams that get consistent value from AI tooling build three layers of structure. None of them are complicated. All of them are deliberate.
Layer 1: Conventions
This is the foundation. Shared project context that every AI tool can use, so the output is consistent regardless of who's prompting.
In practice, this means maintaining a CLAUDE.md or .cursorrules file in your repository that describes your project's architecture, coding standards, and conventions. It means agreeing on prompting patterns for common tasks ("here's how we ask for a new API endpoint") so the team builds on a shared approach rather than reinventing it individually.
It also means establishing decision frameworks. When should a developer use AI for a task versus write it manually? What types of output need extra verification? These aren't rigid rules. They're shared understanding that helps the team make consistent decisions.
Layer 2: Guardrails
Conventions tell developers how to use AI tools. Guardrails ensure the output meets your quality bar regardless of its origin.
This is where CI/CD becomes critical. Your pipeline should enforce the same standards on AI-generated code that it enforces on everything else, and often, it needs to enforce them more strictly. That means comprehensive linting, test coverage thresholds, security scanning, and type checking that run automatically on every pull request.
The key insight is that guardrails aren't about distrusting AI. They're about creating a safety net that lets developers move faster with confidence. When your CI pipeline catches issues automatically, developers can use AI more aggressively because they know the system will catch mistakes. It's the same principle behind test-driven development: the safety net enables speed.
Layer 3: Feedback Loops
Conventions and guardrails create the structure. Feedback loops tell you whether it's working.
This means measuring the things that actually matter: cycle time, defect rates, review turnaround, deployment frequency. Not "how many lines did AI write." That's a vanity metric. The question is whether your team is shipping better software faster.
It also means regular retrospectives specifically about AI tooling. What's working? What's not? What did someone discover this week that the rest of the team should know? This is how institutional knowledge builds: not through documentation mandates, but through regular, lightweight sharing.
What This Looks Like in Practice
Here's a concrete before-and-after for a five-person development team.
Before: Three developers use Copilot occasionally. One uses Claude Code for everything. One doesn't use AI tools at all. There's no shared context, no AI-specific CI checks, and no way to tell whether AI tooling is helping. Code review takes longer because reviewers aren't sure what to look for in AI-generated PRs. The team lead suspects AI is helping but can't quantify it.
After: The team has a shared CLAUDE.md that describes their architecture and conventions. Their CI pipeline runs comprehensive linting, enforces 80% test coverage, and includes security scanning. They've agreed on prompting patterns for their most common tasks. They track cycle time and review turnaround weekly. New developers get an onboarding guide that includes "how we use AI tools on this team."
The result isn't magic. It's engineering discipline applied to a new category of tooling. Cycle time drops because developers aren't reinventing their AI workflows every session. Review quality improves because reviewers know what to check. New team members ramp up faster because there's a shared foundation to build on.
Getting Started
You don't need to build all three layers at once. Start with what will have the most immediate impact.
Step 1: Create shared project context. Add a CLAUDE.md or equivalent to your main repositories. Document your architecture, coding conventions, and any patterns that AI tools should follow. This takes an afternoon and immediately improves output consistency for every developer on the team.
Step 2: Tighten your CI pipeline. If your CI isn't already enforcing linting, test coverage, and type checking on every PR, start there. These guardrails pay for themselves regardless of AI adoption, and they become essential when developers are moving faster with AI assistance.
Step 3: Start measuring. Pick two or three metrics that matter to your team (cycle time, PR turnaround, deployment frequency) and start tracking them. You don't need a dashboard. A weekly check-in where the team looks at the numbers together is enough to start.
If this sounds like the kind of structure your team needs, that's exactly what our AI for Dev Teams service is built for. We embed with your team to set up the conventions, guardrails, and feedback loops that make AI tooling a reliable multiplier, not an inconsistent experiment.
Need help making this real?
We build production AI systems and help dev teams go AI-native. Let's talk about where you are and what's next.